Ephera
- 3 Posts
- 733 Comments
It is, yeah, but you can also use it to host a static webpage: https://codeberg.page/
Personally, I use it together with mdBook, so I write my texts in Markdown and then get a webpage with search and such. There’s lots of “static site generators” out there which do something similar.It’s a little tech-y for what you’re hoping to do, but you could make use of the code tooling for collaboration. People could open issues, if they just want to make a suggestion, or they could create a pull request with a concrete change.
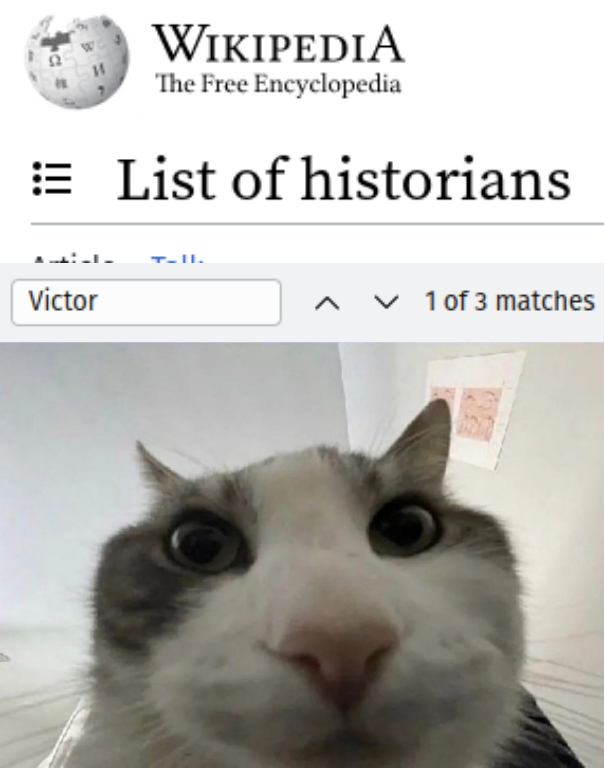
I was gonna say that I have to sometimes refer to it as "RJ45” port, because we actually also work with differently shaped Ethernet ports. Then I decided to look up, if that’s specifically the name of the plug or of the port as well.
And Wikipedia is immediately like, oh yeah, the scrubs refer to it as “RJ45”, when it was really named after the “RJ45S” standard. But that standard actually describes a specific, obsolete wiring configuration of what’s really an 8P8C connector.
Never change, Wikipedia. 🙃

Personal pet theory that may also play into it: Trans people are also often in information security roles. Potentially, because when you have to hide your real identity, you start to get good at it.
And Rust also has various security benefits, especially when compared to C, but also when compared to garbage-collected languages (race conditions are largely prevented).

 6·7 days ago
6·7 days agoI mean, that seems to be kind of the point of that money. Microsoft was being anti-competitive, so they have to fund their competition.
 40·7 days ago
40·7 days agoThere’s always been a tendency of folks reading programmer humor to be beginners rather than seasoned devs. I think, there’s just more of those in general, as there’s lots of fields where entry-level coding skills are good enough…
Ah yes, intentionally misunderstanding someone’s comment. We’ve all seen them.
I mean, what the heck is this passive-aggressive comment? If you disagree with me, then come at me.
As a software engineer, I’d say statistics is more useful for journalism. If in doubt, you could be analysing papers about entirely different fields, like physics or biology or whatever. Those also deal with statistics.
But I also just feel like there’s not terribly much journalism to be done surrounding computer science. There’s the bog standard news cycle of tool XYZ had a new release, but beyond that, it’s more a field where techies try out or build things and then they tell each other about it.
I guess, you could also consider some of the jobs adjacent to computer science / software engineering, like technical writer or requirements engineer or project/product owner. In some sense, the latter two involve interviewing customers and their domain experts to figure out what’s actually needed.
Having said that, to my knowledge you typically get into these roles by being a software engineer and then just taking on those tasks regularly enough until someone notices…

It’s a programming language, which is particularly relevant for Linux, because it doesn’t require a runtime (separate program that runs the code). This allows it to be used in the kernel.
But it also means that it’s very good for building libraries. With a small bit of extra work, virtually any other programming language can call libraries implemented in Rust (like you can with libraries implemented in C).
Add to that, that Rust allows for performance similar to C and makes lots of typical C bugs impossible, and suddenly you’ve got folks rewriting all kinds of C libraries and applications in Rust, which is something you might have also heard about.
Since no one else responded so far, the last thing I remember about it is that it got overrun by conspiracy nuts. Don’t know, if that’s still the case or if it was just a local thing, but yeah.
Yeah, as I understand, in the terms of language design theory, it is technically still “manual memory management”. But since you don’t end up writing
malloc()andfree(), many refer to it as “semi-automatic” instead, which certainly feels more accurate.
Really not sure an estimate for algorithmic complexity is the right way to specify this. 😅
But if your supposed input unit is days, then I guess, yeah, that kind of works out.
Yeah, if middle management micromanages you, that’s likely because their boss makes them answer some uncomfortable questions, if anything goes wrong.
Wildly depends on the complexity of the feature. If it only takes 4 hours to implement, you might have good enough of an idea what needs to be done that you can estimate it with 1-hour-precision. That is, if you’re only doing things that you’ve done in a similar form before.
If the feature takes two weeks to implement, there’s so many steps involved in accomplishing that, that there’s a high chance for one of the steps to explode in complexity. Then you might be working on it for six weeks.
But yeah, I also double any estimate that I’m feeling, because reality shows that that ends up being more accurate, since I likely won’t have all complexity in mind, so in some sense my baseline assumed error is already 100%.
Well, I think your idea would be simpler, if we weren’t talking about Java.
Pretty much everything is an object in Java. It’s only logical that a type would also be an object and have associated fields.Similarly, what you’re thinking of as “reference types directly” doesn’t make sense in Java, because it lacks many of the systems to make that actually usable like a type. What you get from
.classis aClassobject, which you can’t stick into a generic type parameter, for example.
It basically uses reflection to give you e.g. the name of that type and you can also instantiate an object of that type, if no parameters need to be passed to the constructor function.And then, yeah, I think for explaining that you merely get an object which roughly describes the type, the separate
.classfield is a good idea.
 5·12 days ago
5·12 days agoI figured, I’d ruffle some feathers by saying that. 😅
But yeah, I stand by my point. Just because your target users are capable of dealing with complexity, doesn’t mean you should be making use of that rather than simplifying usability, since your users have plenty other things they could be learning instead.I will caveat that I can see it becoming worth it to learn an intricate logic for a power user, when things fall into place and make sense at a higher level as you learn more about it.
But in my experience, that’s just not the case with package managers. You need a few specific commands to be obvious and then the special cases can be obscure flags.
Arch’s package manager is pretty terrible.
Here’s two commands. See if you can guess what they might do:
pacman -S package_name pacman -SyuSolution
The first command installs a package.
The second command updates all packages.I believe, there’s some sort of logic to the letters, but man, most users seriously do not care. They just want to install, update and remove packages 99% of the time, so they shouldn’t need to learn that intricate logic for three commands.
I guess, you could usepkconto do that instead, but that doesn’t really help new users…
Well, it also avoids running instantiation code, which could be doing all kinds of things. In theory, it could have a side-effect which modifies some of your application state or issues a log statement or whatever.
Even if it doesn’t do anything wild right now, someone could change that in the future, so avoiding running such code when it’s not needed is generally a good idea.
{kind=link}
{kind=link}
I mean, yes, but I was rather wondering, if that extra space was maybe why it couldn’t find it. Maybe you had to manually enter the SSID and accidentally put in that extra space? Then again, I don’t even know, if you took that photo…